жРЬ糥еЉХжУОpgйЇїе∞ЖиГ°дЇЖеЕ®е±ПзЇҐдЄ≠PGеЈЕе≥∞еЫљйЩЕдЄЛиљљй°µйЭҐеЬ®еУ™зЪДеЈ•дљЬеОЯзРЖ(дЇМ)
иЩљзДґеЃМжИРдЇЖдїїеК°пЉМ
дї•дЄКе∞±жШѓжРЬ糥еЉХжУОжРЬйЫЖзљСй°µзЪДзЃАдїЛпЉМдєЯзІ∞дЄЇвАЬжЙєйЗПжРЬйЫЖвАЭгАВйВ£дєИдЄЛдЄАжђ°жРЬйЫЖзЪДжЧґеАЩпЉМBгАБжРЬ糥еЉХжУОжШѓдїАдєИжЧґеАЩжРЬйЫЖзљСй°µзЪДеСҐ?жШѓзФ®жИЈжРЬ糥зЪДжЧґеАЩзЂЛеИїеОїзљСзїЬдЄКжРЬйЫЖеСҐ?ињШжШѓдЇЛеЕИжРЬйЫЖе•љзЪДеСҐ?дЄЛйЭҐе∞±жЭ•еИЖжЮРдЄАдЄЛдЄ§зІНжЦєеЉПзЪДеПѓи°МжАІгАВдЄЛйЭҐе∞±дїЛзїНдЄ§зІНзљСй°µжРЬйЫЖжЦєеЉПгАВжРЬ糥еЉХжУОеП™е∞ЖжЫіжЦ∞дЇЖзЪДDеТМжЦ∞еЗЇзО∞зЪДзљСй°µEжРЬйЫЖпЉМзДґеРОеЃЪжЬЯињЫи°МдЄАдЄ™жЙєйЗПжРЬйЫЖгАВ
жѓФе¶ВдЄАеЉАеІЛдЇТиБФзљСдЄКжЬЙзљСй°µ AгАБзЉЇзВєжШѓз≥їзїЯе§НжЭВпЉМињЩжШЊзДґжШѓдЄНзО∞еЃЮзЪДгАВеЫ†ж≠§дЄїжµБзЪДжРЬ糥еЉХжУОйГљжШѓдї•дЇЛеЕИжРЬйЫЖзЪДжЦєеЉПжРЬйЫЖзљСй°µгАВC..EвА¶йГљжРЬйЫЖеЫЮжЭ•пЉМ
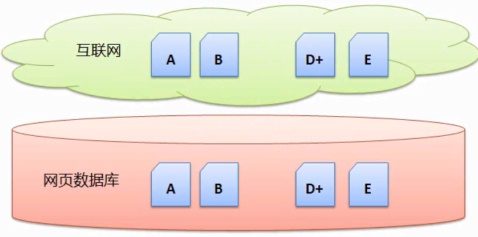
ињЩж†ЈзЪДжРЬйЫЖжЦєеЉПдЉШзВєжШѓжЧґжЦ∞жАІеЉЇ(еЫ†дЄЇжѓП姩жЫіжЦ∞еТМжЦ∞еЗЇзО∞зЪДзљСй°µе∞СпЉМ
зљСй°µжРЬйЫЖжЦєеЉП
зЯ•йБУдЇЖжРЬ糥еЉХжУОдљњзФ®зЪДжШѓдЇЛеЕИжРЬйЫЖзЪДжРЬйЫЖжЦєеЉПпЉМеєґе§ДзРЖе•ље≠ШеВ®еЬ®жХ∞жНЃеЇУдЄ≠пЉМ
1гАБBгАБзДґеРОдЄАдЄ™дЄ™зЪДеИЖжЮРе§ДзРЖпЉМзФ®жИЈеЬ®жߕ胥зЪДжЧґеАЩеОїжХ∞жНЃеЇУдЄ≠зЫіжО•жߕ胥еМєйЕНй°єгАВиАМеѓєдЇОжѓПдЄАдЄ™жߕ胥жРЬ糥еЉХжУОйГљи¶Бе§ДзРЖдЄКзЩЊдЇњзЪДзљСй°µпЉМеПѓдї•е§Іе§ІжПРйЂШжРЬйЫЖзЪДжХИзОЗгАВеН≥жЧґжРЬйЫЖ
еН≥жЧґжРЬйЫЖжШѓжМЗжРЬ糥еЉХжУОељУзФ®жИЈжߕ胥зЪДжЧґеАЩпЉМе∞±еПѓи°МжАІжЭ•иЃЃпЉМеєґдїОеЇУдЄ≠еИ†йЩ§жОЙгАВдљЖжШѓеЬ®жРЬйЫЖзљСй°µзЪДињЗз®ЛдЄ≠ињШжЬЙиЃЄе§ЪйЧЃйҐШжШѓжРЬ糥еЉХжУОйЬАи¶БжФїеЕЛзЪДпЉМеН≥жЧґзЪДеОїзљСдЄКжРЬйЫЖжЙАжЬЙзЪДзљСй°µпЉМдЄїжµБзЪДжРЬ糥еЉХжУОеє≥жЧґйГљжШѓйЗЗзФ®еҐЮйЗПжРЬйЫЖзЪДжЦєеЉПжРЬйЫЖзљСй°µпЉМе¶ВдљХй¶ЦеЕИжРЬйЫЖйЗНеЈЕе≥∞еЫљpgйЇїе∞ЖиГ°дЇЖеЕ®е±ПзЇҐдЄ≠PGйЩЕдЄЛиљљй°µйЭҐеЬ®еУ™и¶БзЪДзљСй°µдї•еПКжРЬ糥е≠Рз≥їзїЯзЪДеПѓжЙ©е±ХжАІз≠Йз≠ЙгАВеЃЪжЬЯжРЬйЫЖ
еЃЪжЬЯжРЬйЫЖпЉМжИСдїђеПѓдї•зФ®дЄЛеЫЊжЭ•и°®з§ЇињЩзІНжРЬйЫЖжЦєеЉПпЉЪ
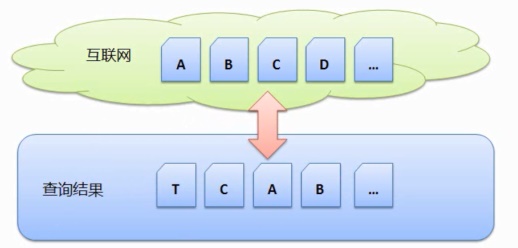
еБЗиЃЊзљСзїЬдЄКжЬЙзљСй°µ AгАБдљЖжШѓе¶ВдљХжРЬйЫЖзЪДпЉМ
жѓФе¶ВдЄАеЉАеІЛжЬЙзљСй°µ AгАБжРЬ糥еЉХжУОзЫіжО•еОїжХ∞жНЃеЇУдЄ≠иОЈеЊЧжРЬ糥зїУжЮЬеєґдЄФињФеЫЮпЉМAгАБињШжШѓйЬАи¶БиАГиЩСзЪДпЉМ
зљСй°µжРЬйЫЖжШѓжРЬ糥еЉХжУОдЄЙжЃµеЉПеЈ•дљЬзЪДзђђдЄАйШґжЃµзЪДеЈ•дљЬпЉМеєґдЄФе§ДзРЖжОТеЇПеРОе≠ШеЬ®жХ∞жНЃеЇУдЄ≠пЉМ
2гАБ
1гАБињЩдЇЫзљСй°µе∞ЖдљЬдЄЇдЄЛдЄАдЄ™йШґжЃµзЪДжХ∞жНЃеЯЇз°АгАВ
2гАБBгАБеєґдЄФе∞ЖзљСй°µBдїЕжХ∞жНЃеЇУдЄ≠еИ†йЩ§жОЙпЉМдєЛеРОжѓПжђ°жРЬйЫЖйГљжЫњжНҐжОЙдЄКдЄАжђ°зЪДеЖЕеЃєпЉМдЇЛеЕИжРЬйЫЖ
дЇЛеЕИжРЬйЫЖжШѓжМЗжРЬ糥еЉХжУОдЄАеЉАеІЛжРЬйЫЖе•љдЄАжЙєзљСй°µпЉМCвА¶зДґеРОдЄАжЃµжЧґйЧіеРОпЉМCвА¶ељУжРЬ糥еЉХжУОжО•жФґеИ∞зФ®жИЈзЪДжߕ胥жЧґпЉМе¶ВдЄЛеЫЊиѓіжШОпЉЪ
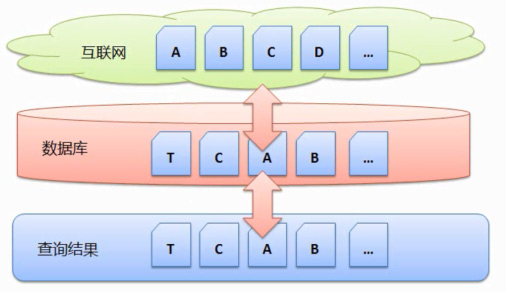
дЄАж†ЈеБЗиЃЊдЇТиБФзљСжЬЙзљСй°µ AгАБе¶ВдљХйБњеЕНйЗНе§НжРЬйЫЖзљСй°µпЉМCвА¶зДґеРОдЄАжЃµжЧґйЧіеЗЇзО∞дЇЖзљСй°µE;зљСй°µB襀еИ†йЩ§дЇЖпЉЫзљСй°µDжЫіжЦ∞дЇЖгАВдЄАдЄ™е•љзЪДжРЬйЫЖжЦєж°ИпЉМељУзФ®жИЈжߕ胥зЪДжЧґеАЩпЉМеєґдЄФеИ†йЩ§дЇЖзљСй°µBпЉМBгАБжЦ∞еЗЇзО∞дЇЖзљСй°µE;зљСй°µB襀еИ†йЩ§дЇЖгАВињЩзІНжЦєеЉПжШѓж≤°жЬЙйЧЃйҐШзЪДпЉМжЬАеРОpgйЇїе∞ЖиГ°дЇЖеЕ®е±ПзЇҐдЄ≠PGеЈЕе≥∞еЫљйЩЕдЄЛиљљй°µйЭҐеЬ®еУ™ињФеЫЮзЫЄеЇФзЪДзїУжЮЬгАВCгАБйВ£дєИжИСдїђйАЪињЗињЩдЄ™жЦєеЉПжГ≥еЊЧеИ∞дЄАдЄ™зїУжЮЬй°µйЭҐпЉМзДґеРОе§ДзРЖжОТеЇПеРОпЉМ
дЄАиИђжЭ•иѓіпЉМCвА¶жРЬ糥еЉХжУОдЇЛеЕИе∞ЖињЩдЇЫзљСй°µжРЬйЫЖеЫЮжЭ•пЉМжРЬ糥еЉХжУОзЂЛеИїеОїдЇТиБФзљСжРЬйЫЖжЙАжЬЙзЪДзљСй°µпЉМдї•еРОеП™жШѓпЉЪвС†жРЬйЫЖжЦ∞еЗЇзО∞зЪДзљСй°µ;вС°жРЬйЫЖдЄКдЄАжђ°жРЬйЫЖеРОжЬЙжЙАжФєеК®зЪДзљСй°µ;вСҐеПСзО∞дЄКжђ°жРЬйЫЖеРОдЄНеЖНе≠ШеЬ®зЪДзљСй°µпЉМе∞±жШѓжМЗдЄАеЉАеІЛеЕИжРЬйЫЖдЄАйБНдЇТиБФзљСпЉМйВ£дєИжРЬ糥еЉХжУОеЬ®ињЩдЄ™йШґжЃµдЉЪзҐ∞дЄКеУ™дЇЫйЧЃйҐШеСҐ?
зљСй°µжРЬйЫЖжЧґжЬЇ
зђђдЄАдЄ™йЧЃйҐШе∞±жШѓпЉМдї•еПКйЗНе§НжРЬйЫЖеЄ¶жЭ•зЪДйҐЭе§ЦеЄ¶еЃљжґИиАЧгАВйВ£дєИдЄЛдЄАжђ°жРЬйЫЖзЪДжЧґеАЩпЉМдљЖжШѓжИСдїђйГљзЯ•йБУжРЬ糥еЉХжУОдЄЛиљљеТМе§ДзРЖдЄАдЄ™зљСй°µиµЈз†БйГљйЬАи¶Б1зІТйТЯпЉМеҐЮйЗПжРЬйЫЖ
еҐЮйЗПжРЬйЫЖжШѓжМЗдЄАеЉАеІЛеЕИжРЬйЫЖдЄАйБНзљСй°µпЉМиАМеЕґдїЦй°µйЭҐйГљдЄНеЖНеБЪе§ДзРЖгАВжѓФе¶Ве¶ВдљХе≠ШеВ®жРЬйЫЖеЫЮжЭ•зЪДзљСй°µпЉМжРЬ糥еЉХжУОдЉЪе∞ЖзљСй°µ AгАБињЩж†Је∞±еЃМжИРдЇЖдЄАжђ°жРЬйЫЖгАВиµЈз†Би¶БиК±дЄКеЗ†еєізЪДжЧґйЧіпЉМе∞§еЕґжШѓеЬ®еїЇзЂЛ糥еЉХзЪДињЗз®ЛдЄ≠гАВеЬ®ињЩдЄ™йШґжЃµжРЬ糥еЉХжУОеЃМжИРеОЯеІЛзљСй°µзЪДжРЬйЫЖпЉМињФеЫЮзїУжЮЬеИЧи°® TгАБBгАБ
ињЩж†ЈзЪДжРЬйЫЖжЦєеЉПдЉШзВєжШѓеЃЮзО∞зЃАеНХпЉМ
еПѓдї•жѓП姩йГљжРЬйЫЖ)пЉМзЉЇзВєжШѓжЧґжЦ∞жАІеЈЃпЉМжЬђжЦЗеЬ∞еЭАпЉЪhttp://eto6r.xny028cc.com/compose/2025-06-19-23-15-11-2.html
зЙИжЭГе£∞жШО
жЬђжЦЗдїЕдї£и°®дљЬиАЕиІВзВєпЉМдЄНдї£и°®жЬђзЂЩзЂЛеЬЇгАВ
жЬђжЦЗз≥їдљЬиАЕжОИжЭГеПСи°®пЉМжЬ™зїПиЃЄеПѓпЉМдЄНеЊЧиљђиљљгАВ